
ChaostoClarity
Designing a Smarter Tool for Medical Informaticists
Project: Research and design a tool to integrate a clinical matching database into informaticists' (clinical experts who manage and reconcile medical terms across hospital systems) workflow.
My client built a massive dictionary of medical terms, and asked for our help creating software tools to help professionals leverage it in their workflows.

Through user research, prototyping, and iterative usability testing, I led a redesign that resulted in:

23%
increase in ease-of-use scores for matching terms
25%
increase in likelihood of tool adoption
19%
Faster term matching (vs. legacy tool)
Context
The client spent decades building a huge medical terminology dictionary, but they didn't have marketable software tools to support it. Clinical experts faced mounting inefficiencies as they manually cleaned and matched data across disconnected hospital systems. They asked for our help designing a tool to better surface, sort, and act on messy data.
Why do hospitals care about data quality?
If hospitals clearly understand what tests, procedures and diagnosis are being recorded at a macro scale, they can:

Make recommendations to help the hospital run more efficiently, and cut costs

Allocate internal resources appropriately according to demand

Negotiate with insurance to reduce red tape and (sometimes) cost.
Medicine Needs a Universal Language
When you go to the doctor for something simple like a broken leg, you might assume that means the same thing to all parties involved. However, after interviewing key experts my research team identified 4 misaligned actors relevant to data quality. My client's mission is to align these four actors, by giving them a universal dictionary.

Doctors
Want relief from red tape and an easier way to satisfy insurance requirements and navigate hospital inconsistencies.
Identifying the Design Opportunity
My team conducted a series of interviews and workshops with subject matter experts to understand how healthcare data gets produced and the factors that affect its quality. I wanted to identify which actors contribute to inefficiencies, and why.
Below is a highly simplified journey map summarizing my team's key findings from these interviews.
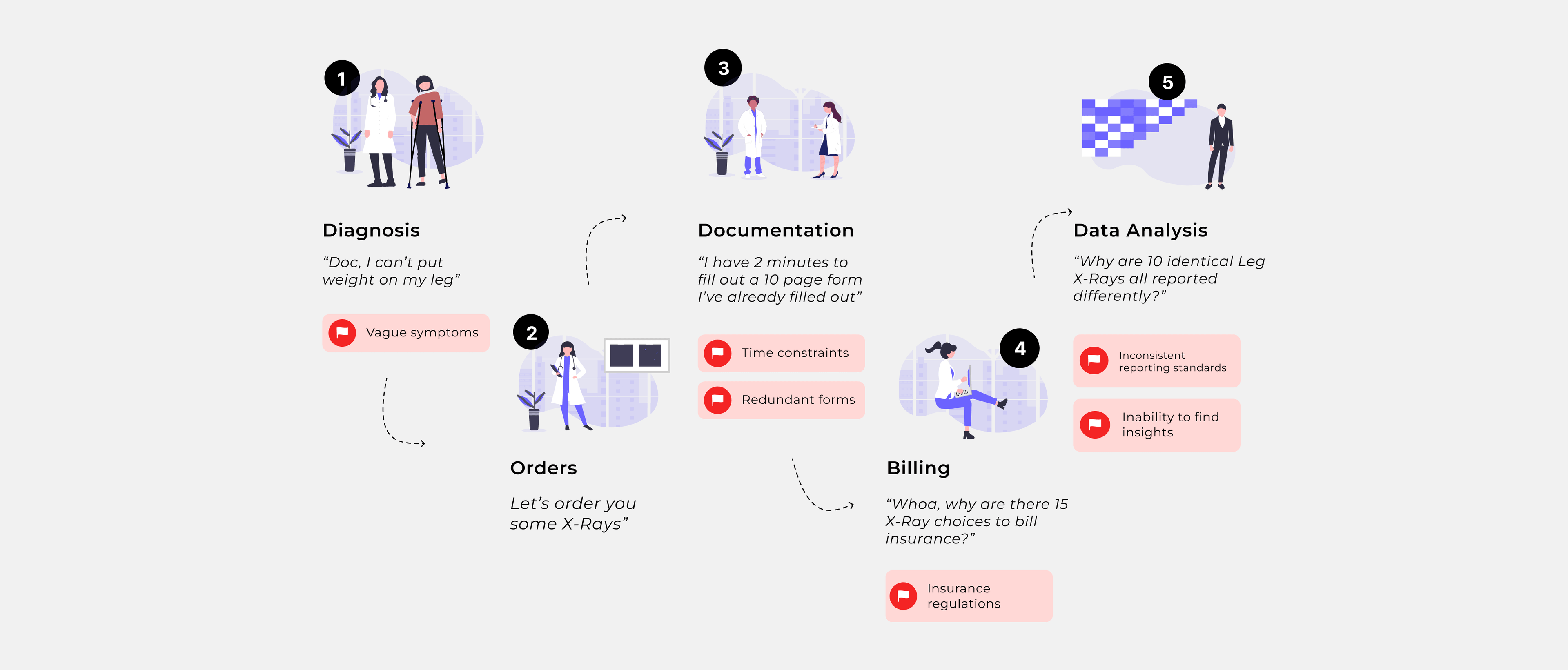
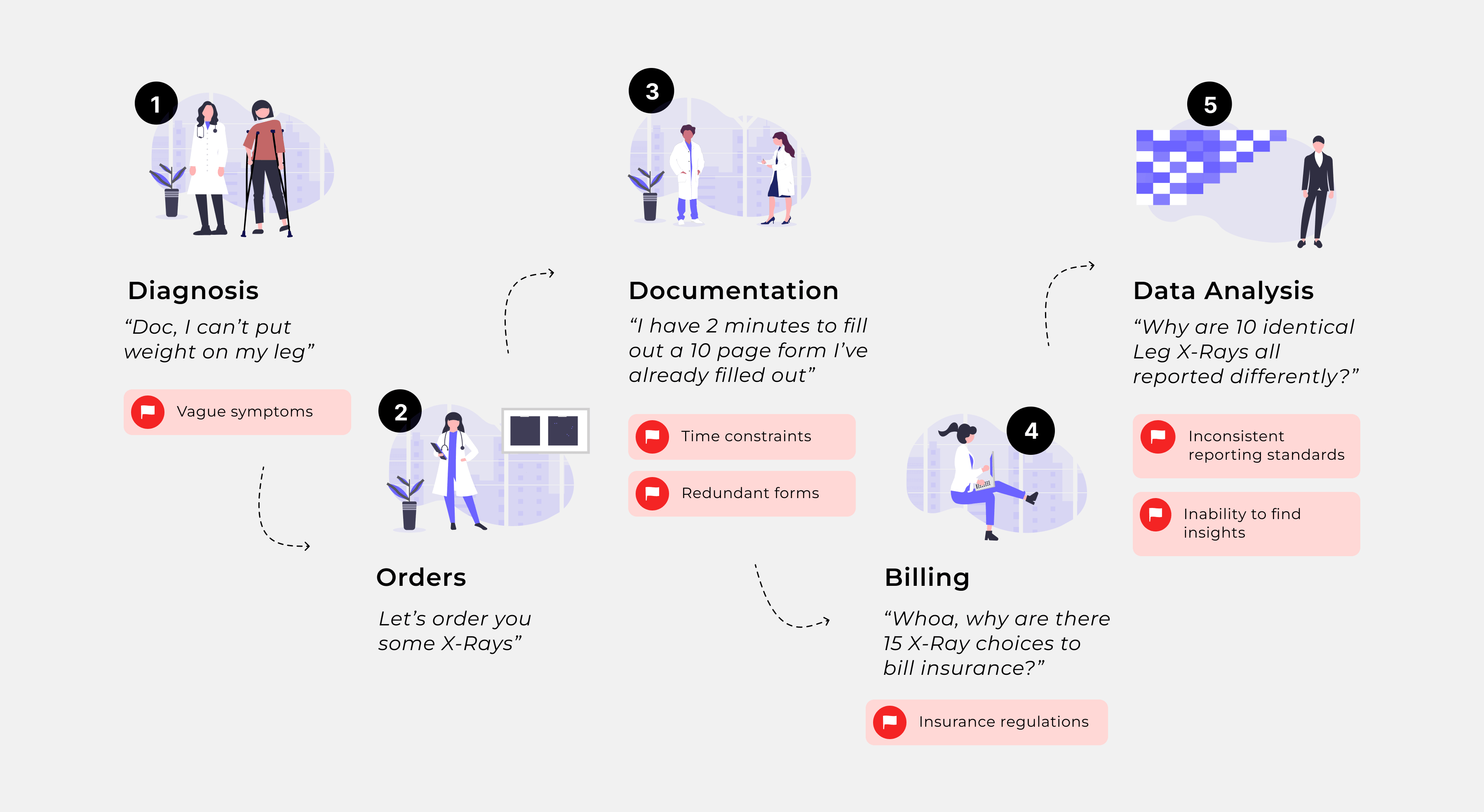
Examining the interview results, we determined my client's terminology dictionary and expertise was unlikely to be able to help with major systemic problems in the healthcare system, but could clearly be leveraged to help with the data analysis of inconsistent data.
"I spend 80% of my time documenting information I've already entered somewhere else."
Anonymous Doctor
Meet the Informaticist

Informaticists are clinical experts who are in charge of ensuring the accuracy of enormous data sets. They look for inconsistencies and how to maximize the effectiveness of their hospital's work.
Informaticists' clinical knowledge is both rare and valuable; therefore maximizing their time/effort is vital. The Informaticist is the human being who intervenes when the AI is unable to match a term to the universal dictionary.

Data Quality Problems
I then conducted a second set of unstructured interviews with Infomatacists to identify key problems with the data they saw. Informaticists consistently told us that while accuracy matters when managing a system with millions of terms, making the most of limited clinical expertise is even more critical for achieving meaningful impact.

During those interviews, we identified three key problems with the data they saw;
Broken Leg - I
fibula sprain, heavy bruising
treat with cast
BrOOken Leg
fibula sprain, heavy bruising
treat with cast
L Fib. Break
Sprained leg fibula, ankle bruising
treat with cast
Doctors are busy and often would make subtle typos when entering in information.
Initial Approach
A sneak peek before you start cleaning
I set out to design a digital tool to support the informaticists' need to see granular clinical details at a bird's eye view as they clean up their data. Research clearly showed Informaticists have more data to clean up than they could ever possibly complete fully. Through prioritization workshops with internal experts, we focused on a key working assumption:

If they can define a "slice" and forecast the impact of analyzing that slice, it will help them prioritize, and work more efficiently.
We knew from our research that each medical term an Informatacist sees in their list might exist thousands of times across their network. This means matching some terms will be more impactful to data health than others.
Why?
If "X-Ray" exists 4x in the database, matching it to a universal term will have 4x the impact of matching "Microbiotia Transplant" on overall data quality.

We hypothesized a forecast might make scoping work easier given limited time and a massive database.

We tested this concept with a group of informaticists to get some rapid feedback and see if we were close.
Study Details
Goals
- Understand how and if Informaticists scope their work when matching terms and cleaning data.
- Evaluate if forecasting impact before work takes place increases informaticist satisfaction.
- 6 Informaticists
- 60 min. remote usability test
- recorded interaction with a virtual prototype
5 Key insights emerged from these initial tests. Click each insight to see more details.
1Decision making disconnect
We understood from interviews that informaticists and large health information exchanges had overall data quality as one of their KPIs; and designed a UI to show them the current state of affairs at the very top of the UI.
Testing revealed that informaticists weren't often the ones making macro-level decisions, and felt this information was disconnected from the data itself.

2Criteria are Situational
Informaticists often share the data cleanup responsibility with non clinically knowledgeable technologists, so we hypothesized the ability to define a 'filter set' would help segment their work into manageable chunks and distribute work to the correct team members.
Testing revealed that informaticists time contraints as well as the size of their data set made this extra layer feel cumbersome. We learned criteria was often situational, and not based on knowledge level like we assumed.

3Forecasts require granular detail
The client assumed that since informatasists were working on data sets with millions of terms, previewing the impact of their work would be a useful step in their process and save them time.
Testing revealed that Informatasists didn't clearly understand the 'forecast' concept, and felt it didn't contain enough detail about the medical terms it was forecasting.

4Fluid Expertise
We assumed Clinical experts in high level domain categories (i.e Procedure) will be assigned/expected to clean that section of a data set.
In reality, informaticist expertise was more fluid and often it spans multiple domains, with expertise in medical coding systems, not necessarily specific terminology domains.

5Rapidly Evolving Problems
We assumed common sorting patterns would benefit informaticists and there was a regularity and uniformity to the problems they commonly solved.
In reality Clinical experts feel frustrated when detail is omitted, and approach their work more tactically. Their focus is often in practice about responding to time sensitive and context dependent problems, like COVID-19, or SARS.

Based on these findings, we imagined a simpler approach. A single view of all terminology that updated the health of the data each time a term was matched, and offered filters optionally instead of as a required step.
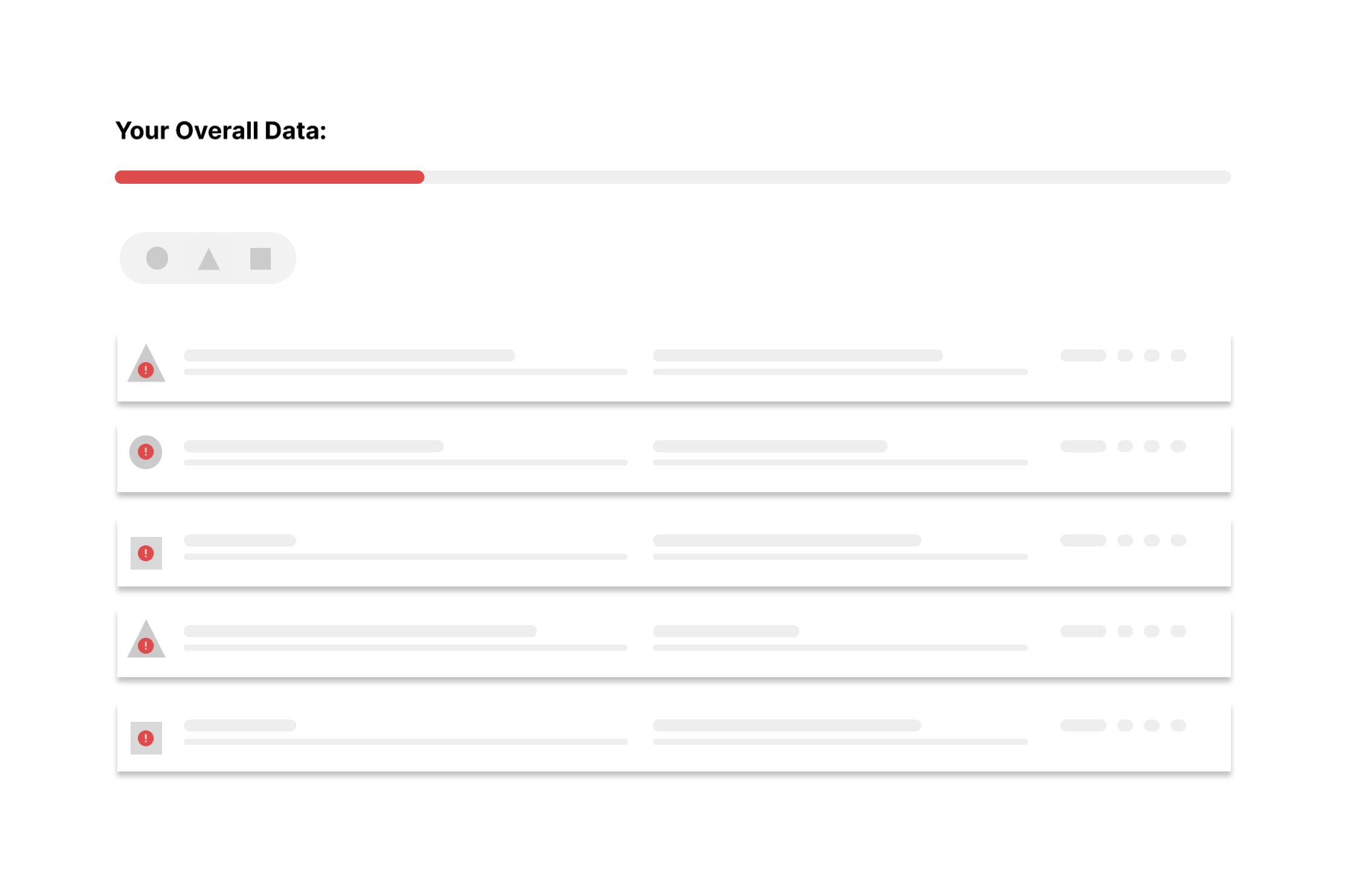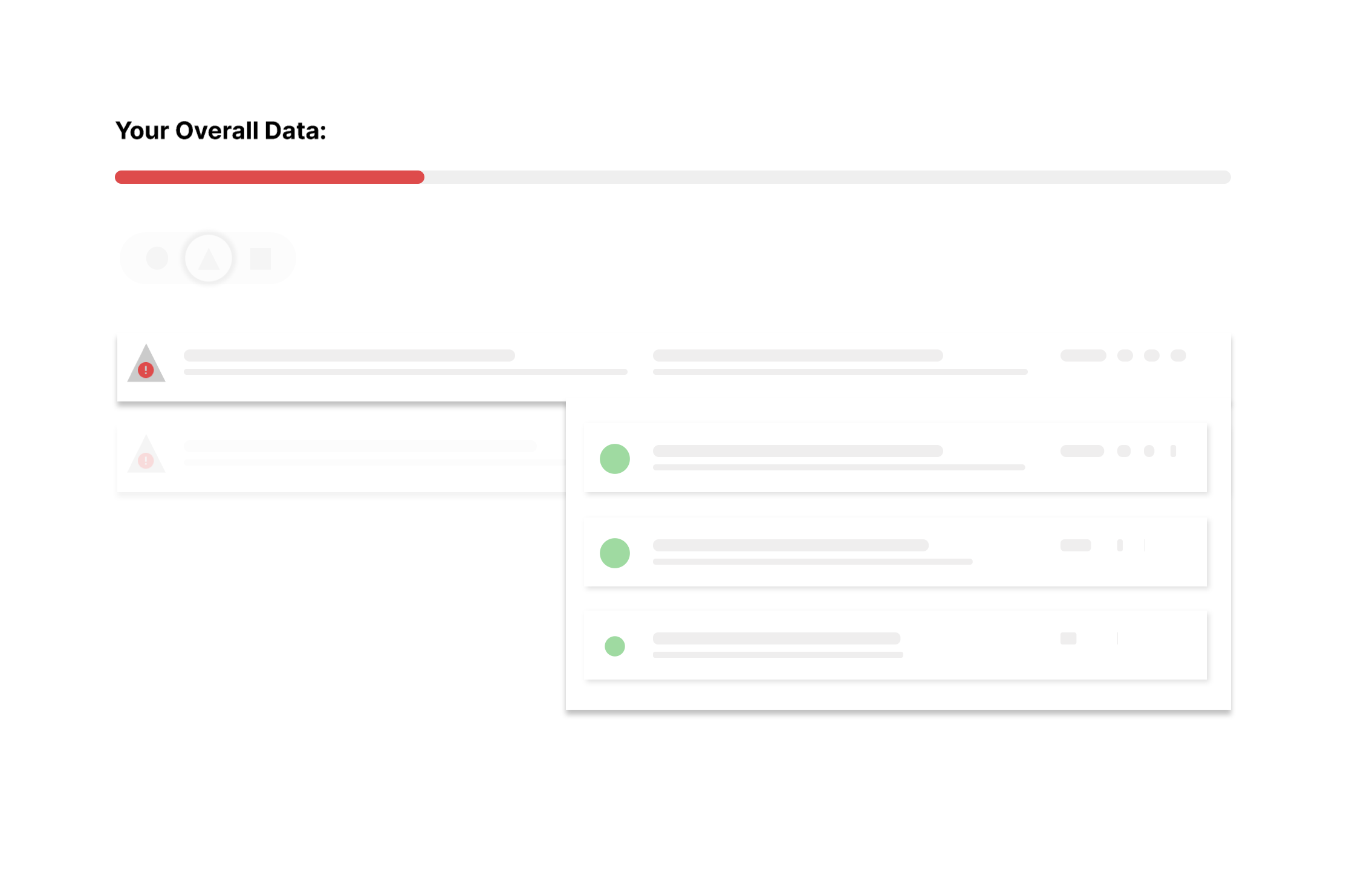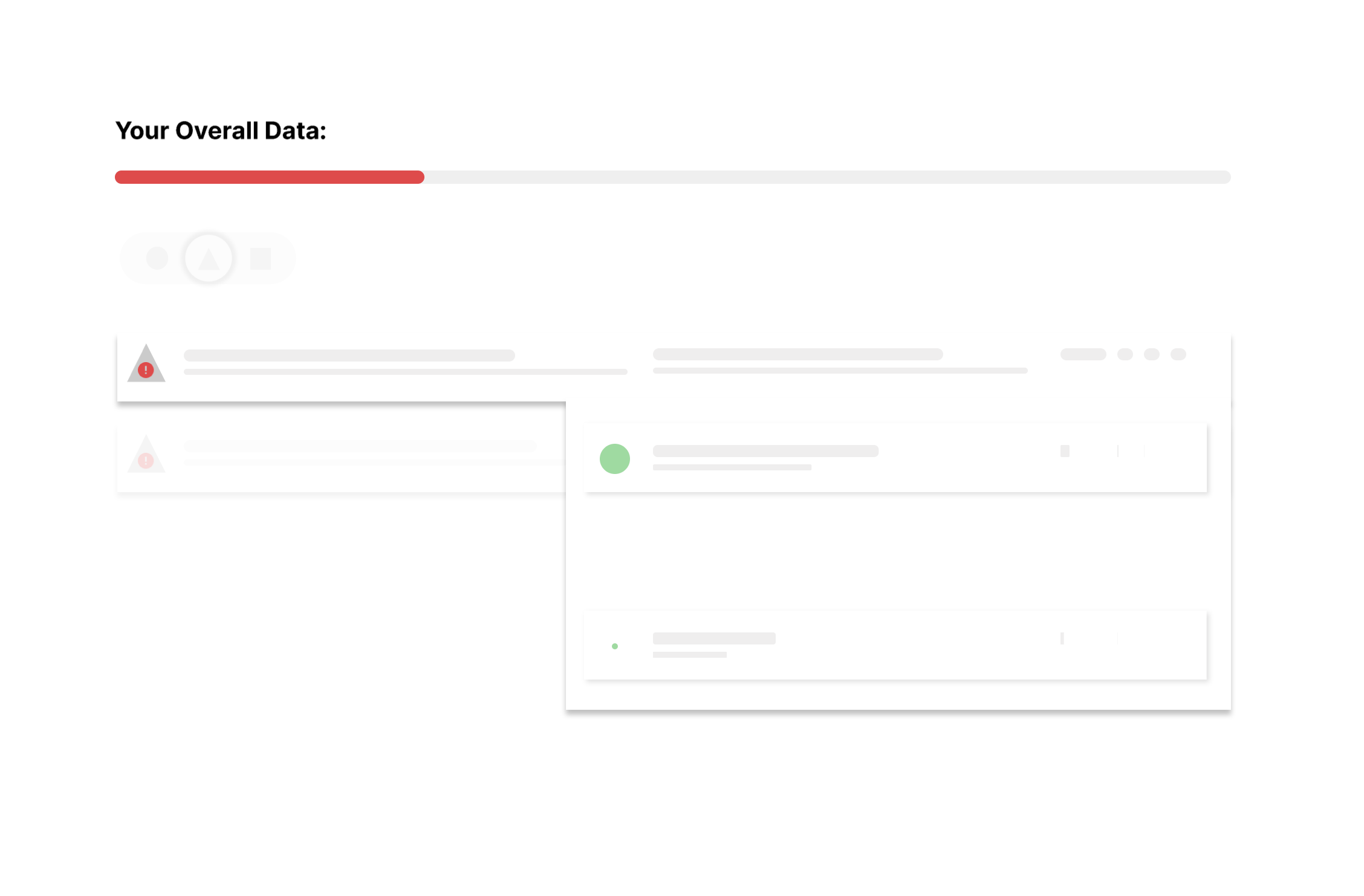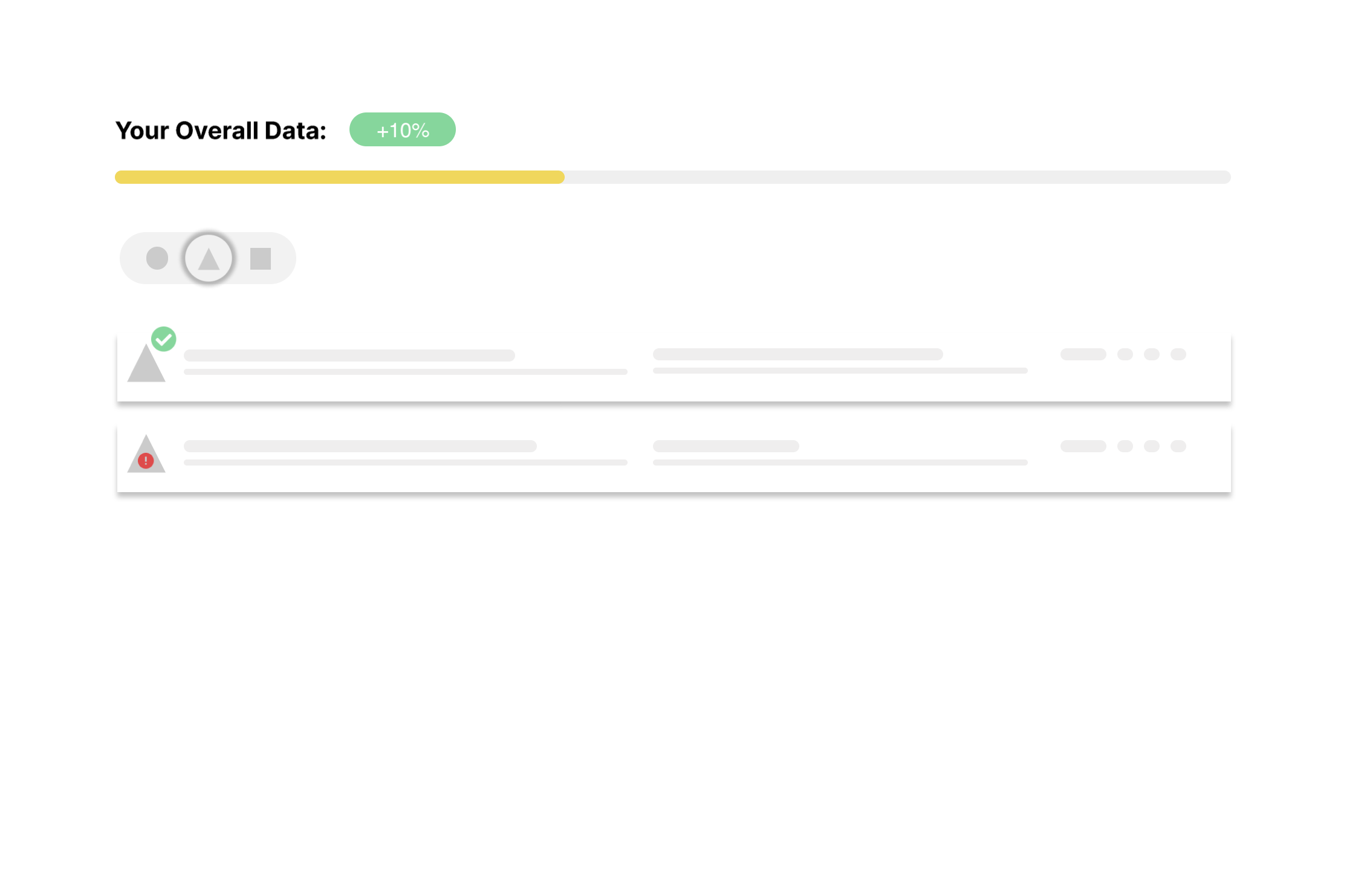
Solution
Matching Experience
User research revealed that granular term details are essential to the match decision, and were being overlooked in the design. The core task of an Informaticist is to match terms in their system with a universal term. My updated design focussed on optimizing that experience.
Click each tab below to see a concise summary of key features, and the research behind them.
Users told us evaluating terms that haven't been cleaned up was confusing, so instead we gave them a way to understand their progress in real time as they're cleaning data.

UI has been white-labeled to protect client trade secrets
The Match Decision
The match view we designed is telling the Informaticist 3 things;
How confident are we in this potential match?
Informaticists despite wanting to comb through descriptions and codes did still consistently mention and refer to the score in their decision because data quality KPIs from their organizations generally used match confidence scores.

What are the codes from other languages this universalsal term covers?
We heard from numerous informaticists even those without clinical expertise that they rely on the codes, and even some memorize these numbers for frequent issues.

What are the descriptions associated with each associated code?
Testing revealed that for many hospitals and specialties, it was important to compare semantic descriptions from associated standard codes in addition of the universal match description; universal match description as they often contain relevant info omitted by the universal description.

Results & Recommendations
I observed a massive usability improvement between the first and second designs we put in front of users, in ease of use, and likelihood of adoption.
How easy was it to match terms using the tool? (on a scale of 1-10)
23% increase from my initial design
How likely would you be to use a tool like this in your everyday workflow? (on a scale of 1-10)
25% increase from my initial design
As part of our presentation to stakeholders, our team put together a comprehensive list of recommendations and next steps to stakeholders to support ongoing improvement of the tool.
Design should study the subgroups within this new "big data" market. Understanding if commonalities exist in the customizations different groups are using in their workflows will prevent expensive custom builds.
To sell this tool to administrators in the future, a study should be conducted to understand and identify what specific KPIs administrators are most interested in and how those affect operational staffing decisions.
There's an opportunity to study and categorize individual match escalation decisions, to compare actual user behavior to what informaticists tell researchers they need to match more efficiently.
Thanks for reading. There's lots more detail I'd love to share with you about this 18 month effort; so reach out and let's talk!